In various neural netwoks, to find a sufficiently good solution, it is necessary to run the gradient-based algorithms described earlier multiple times. Therefore, it is essential to use different randomly selected starting points and compare the performance of each.
The gradient of the error function in deep neural networks can be efficiently evaluated using error backpropagation, and this information can be used to significantly speed up the training of the network.
Taking the following equation as an example,

Where the error surface is specified $\text{d}$ and $\text{H}$ since the matrix $\text{H}$ is symmetric. Therefore, the position of the minimum of the quadratic approximation is determined by the paramters of $O({W^2})$, and this information is requied to fine the minimum. If gradient information is not used, a computational cost of $O({W^3})$ is needed.
However, If an algorithm that uses gradient information is employed, since $\nabla E$ is evaluated, and the function's minimum of $O(W)$ can be found through gradient evaluation. Additionally, using error backpropagation requires only $O(W)$ per calculation, so the minimum can be found through $O({W^2})$
The simplest method of using gradient information is to update the weights.
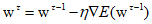
Where $\eta $ is a parameter known as the learning rate and is positive. The learning rate affects the speed and performance of the model's training. After each update, the gradient for the new weight vector ${{\text{w}}^{\tau + 1}}$ is recalculated, ans this process is repeated.
At each step, the weight vector moves in the direction where the error function decreases the fasets, which is why this method is called gradient descent. Since the error function is defined over the training set, the entire training set must be processed at each step to calculate $\nabla E$. When the entire dataset is used at once, this is referred to as the batch method.
In deep learning, the more data available, the more effective it is (provided the data is of good quality). Therefore, the most widely used training algorithm for large datasets is Stochastic Gradient Descent (SGD). SGD updates the weight vector based on just one data point at a time.
These updates are performed iteratively, cycling through the data, and passing through the entire training set is referred to as a training epoch. compared to batch gradient descent, Stochastic Gradient Descent efficiently handles redundancy within the data.
However, one of the drawbacks of Stochastic Gradient Descent is that the gradient of the error function calculated at a data point provides a very noisy estimate of the gradient of the error function calculated over the entire dataset. Therefore, this drawback can be mitigated by using a small subset of data points, known as a mini-batch, to evaluate the gradient at each iteration. When determining the optimal size of a mini-batch, it is important to note that the error in calculating the mean from $N$ samples is proportional to $\sigma /\sqrt N $, where $\sigma $ is the standard deviation of the distribution generating the data. Additionally, an important consideration when using mini-batches is that the constituent data points should be randomly selected from the dataset, which helps in avoiding local minima.
'Deep Learning' 카테고리의 다른 글
| 64_Normalization (0) | 2024.02.02 |
|---|---|
| 63_Learning Rate Schedule (0) | 2024.02.01 |
| 61_Gradient Descent (0) | 2024.01.30 |
| 60_Multilayer Networks and Activation Function (0) | 2024.01.29 |
| 59_Generative Classifiers(2) (1) | 2024.01.28 |