Today, I plan to make some modifications to the existing DNN model coda and address the overfitting issue that has occurred. Until now, training has been conducted using the CPU, but PyTroch allows for model training using the GPU. In fact, setting up this environment involved numberous version mismatch errors, leading to several rebuilds of the conda envirionment.
It is recommended to carefully match versions from the beginning and install CUDA, cuDNN, and PyTorch accordingly.
If CUDA, cuDNN, CUDA Toolkit, and PyTorch have been successfully installed, we can easily set up to use the GPU.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
It a GPU is available, the device will be set to cuda, otherwise it will be set to cpu. Lets use this device setting to make additions to the DNN code.
model = DNN().to(device)
training_losses, test_losses = train(model, training_loader, test_loader, device)
After setting the device, we need to transfer the model and data to the GPU, This is done using '.to(device)'. As in the above code, transfer the model to the GPU and add the device as an argument to the input values when entering the training function.
def train(model, training_loader, test_loader, device, epochs = 10):
training_losses = []
test_losses = []
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in tqdm(training_loader, desc=f"Epoch {epoch+1}/{epochs}"):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
training_losses.append(running_loss / len(training_loader))
model.eval()
test_loss = 0.0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_losses.append(test_loss / len(test_loader))
print(f'Epoch {epoch+1}, Training Loss: {training_losses[-1]:.4f}, Test Loss: {test_losses[-1]:.4f}')
return training_losses, test_losses
Before processing each batch of data, the data must be transferred to the device. Therefore, it's necessary to apply '.to(device)' to both inputs and labels to transfer the data to the GPU. With these simple modifications, you can switch from CPU based computations to GPU based operations. When comparing the results, they are as follows.
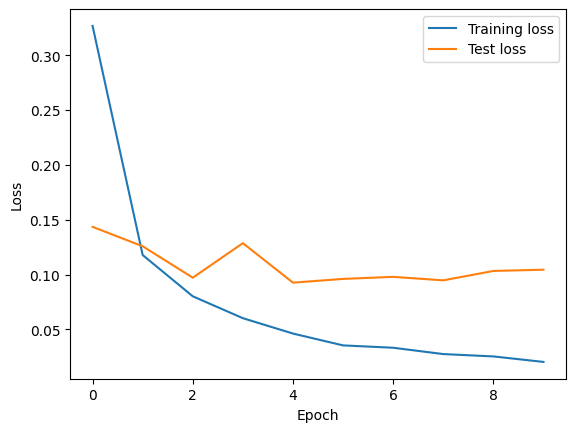
CPU
Training loss : 0.0203
Test loss : 0.1044
Time : 83s
GPU
Training loss : 0.0241
Test loss : 0.0978
Time : 57s
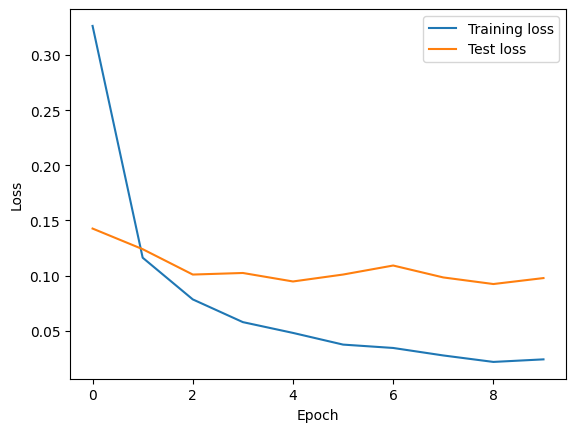
Despite having three hidden layers, using the GPU resulted in approximately a 30% faster performance.
Utilizing a GPU becomes even more effective as the model complexity and computational difficulty increase.
Now, let's address the overfitting issue. The simplest method is to add dropout layers.
class DNN(torch.nn.Module):
def __init__(self):
super(DNN, self).__init__()
self.input = torch.nn.Linear(28*28, 512)
self.hidden1 = torch.nn.Linear(512, 256)
self.hidden2 = torch.nn.Linear(256, 128)
self.hidden3 = torch.nn.Linear(128, 64)
self.dropout = torch.nn.Dropout(0.3)
self.output = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.input(x))
x = self.dropout(x)
x = torch.relu(self.hidden1(x))
x = self.dropout(x)
x = torch.relu(self.hidden2(x))
x = self.dropout(x)
x = torch.relu(self.hidden3(x))
x = self.dropout(x)
x = self.output(x)
return x
The dropout rate was set to 30%. This means that only 70% of the data is used for training. The results are as follows.
Add Dropout layers
Training loss : 0.0643
Test loss : 0.0888
Time : 59s
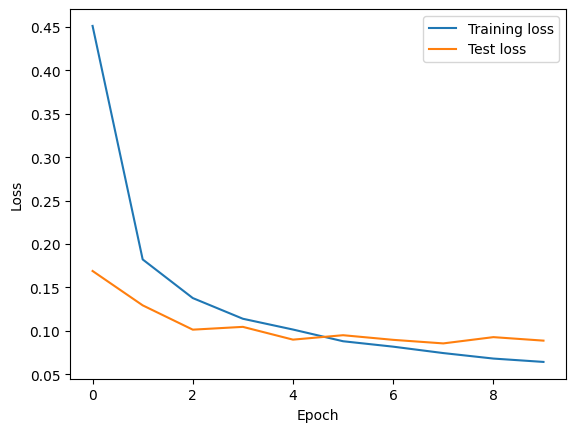
Adding dropout layers alone resulted in a further decrease in test loss compared to before their addition, and the loss continued to decrease throughout the training process. Therefore, adding dropout layers alone was sufficient to address overfitting in this model.
'Deep Learning' 카테고리의 다른 글
| 111_MNIST Classification with Keras (vs PyTorch) (0) | 2024.03.20 |
|---|---|
| 103_Code Modification (0) | 2024.03.12 |
| 101_Overfitting (0) | 2024.03.10 |
| 100_DNN Example using PyTorch (0) | 2024.03.09 |
| 99_Simple CNN Example Using PyTorch (0) | 2024.03.08 |